What Is TokenSpeed?
TokenSpeed is a preview-stage LLM inference engine built by LightSeek for agentic workloads, and TokenSpeed is one of the best LLM Inference Engines tools for teams serving agentic LLM workloads on GPUs. The project claims TensorRT-LLM-level performance with vLLM-level usability, and the repo documents a local-SPMD compiler, a C++ plus Python scheduler, and pluggable kernel layers aimed at Blackwell-class hardware.
Quick Overview
| Attribute | Details |
|---|---|
| Type | LLM Inference Engines |
| Best For | teams serving agentic LLM workloads on GPUs |
| Language/Stack | C++, Python, CUDA, local-SPMD compiler, layered kernel registry |
| License | N/A |
| GitHub Stars | N/A as of Feb 2026 |
| Pricing | Open-Source |
| Last Release | Preview release — date not stated |
Who Should Use TokenSpeed?
- GPU infra teams evaluating next-generation serving stacks for agentic traffic patterns that need high throughput and low CPU overhead.
- Model platform engineers who want explicit control over parallelism, KV cache ownership, and request scheduling without hand-writing the entire distributed runtime.
- Performance-focused startups benchmarking Blackwell or Hopper deployments where kernel choice and overlap timing materially affect cost per token.
- Researchers and systems engineers comparing compiler-driven inference architectures against vLLM style serving loops and NVIDIA-centric baselines.
Not ideal for:
- Production deployments today, because the repo explicitly says this is a preview release and warns against using it for production.
- Teams that need mature model coverage immediately, since Qwen 3.6, DeepSeek V4, and MiniMax M2.7 support is still in progress.
- Users who want a stable turnkey API, because the runtime is still evolving and several features remain under active merge work.
Key Features of TokenSpeed
- Local-SPMD modeling layer — TokenSpeed uses module-boundary placement annotations plus a static compiler to generate collective communication automatically. That means fewer hand-written tensor-parallel paths and less room for distributed runtime drift.
- Finite-state scheduler — The scheduler models request lifecycle, KV cache ownership, and overlap timing as a finite-state machine. That design makes cache reuse safer at compile time and gives the runtime a clearer execution contract.
- C++ control plane, Python execution plane — TokenSpeed splits low-latency orchestration from higher-level model execution. The C++ side handles scheduling pressure, while Python keeps the model logic accessible for iteration.
- Pluggable kernel registry — The kernel stack is layered and exposes a portable public API with a centralized registry. That lets TokenSpeed swap specialized kernels without rewriting the serving stack.
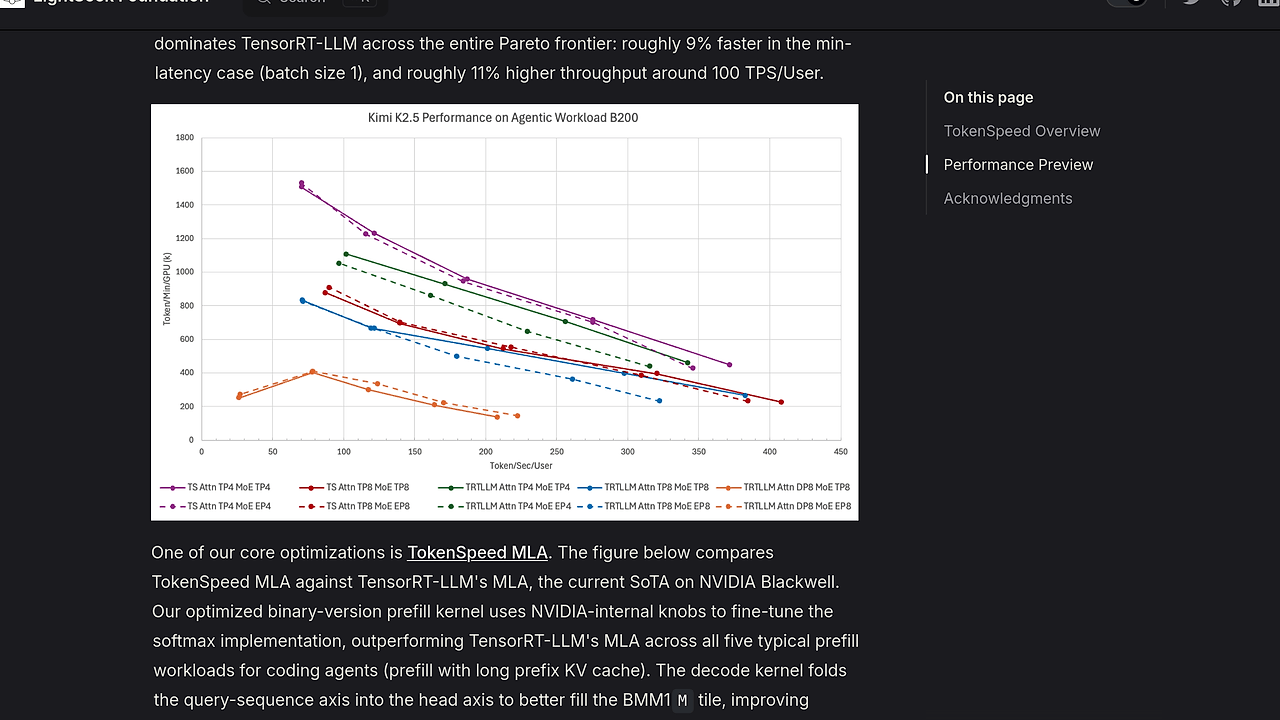
- Fast MLA implementation on Blackwell — The repo calls out one of the fastest MLA implementations on Blackwell for agentic workloads. That matters when attention bottlenecks dominate decode latency on large models.
- SMG-integrated AsyncLLM entrypoint — TokenSpeed uses AsyncLLM to reduce CPU-side request overhead. In practice, that should help keep host orchestration from becoming the bottleneck under high concurrency.
- Preview-focused performance work — The public status notes ongoing work for PD, EPLB, KV store, Mamba cache, VLM, metrics, Hopper optimization, and MI350 optimization. That tells you the runtime is still being actively reshaped rather than frozen for compatibility.
TokenSpeed vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| TokenSpeed | Agentic GPU serving on bleeding-edge hardware | local-SPMD compiler plus typed scheduler and custom kernels | Open-Source |
| TensorRT-LLM | NVIDIA-first production inference | Deep integration with NVIDIA TensorRT and optimized kernels | Open-Source |
| vLLM | General-purpose serving with broad adoption | Mature PagedAttention stack and wide community support | Open-Source |
| SGLang | Structured generation and agent-oriented serving | Programmatic control flow around model calls | Open-Source |
Pick TensorRT-LLM if your team wants the most established NVIDIA path and can live with more explicit tuning. Pick vLLM if you need broad model compatibility and a safer default for production rollouts.
Pick SGLang if your priority is programmatic agent flow rather than squeezing every last token/sec from the GPU. If you are wiring orchestration above the server layer, TokenSpeed pairs well with OpenSwarm for multi-agent control and OpenTrace for request-level tracing.
How TokenSpeed Works
TokenSpeed uses a compiler-driven serving model instead of a purely dynamic runtime. The local-SPMD design lets the compiler derive collective communication from annotated module boundaries, so the user defines intent and the system generates the parallel communication plan.
The scheduler is the second major abstraction. TokenSpeed splits responsibilities between a C++ control plane and a Python execution plane, then encodes request lifecycle state, KV cache ownership, and overlap timing as a finite-state machine. That structure is important because it lets the runtime enforce safe cache reuse at compile time instead of discovering conflicts after the server is already hot.
The kernel system sits underneath both layers. TokenSpeed exposes a portable public API with a centralized registry, which is how it can swap in specialized kernels like its Blackwell-focused MLA path without making the rest of the server aware of hardware-specific details.
git clone https://github.com/lightseekorg/tokenspeed.git
cd tokenspeed
python -m pip install -e .
tokenspeed serve --model Qwen/Qwen2.5-32B-Instruct --tp 4 --kv-cache fp8
That sequence clones the repo, installs TokenSpeed in editable mode, and starts a server with a model plus a few typical performance flags. Expect the exact flag names to track the docs index and recipes pages, because this is a preview release and the CLI surface is still moving.
Pros and Cons of TokenSpeed
Pros:
- Compiler-guided parallelism reduces the amount of hand-written distributed logic.
- Typed KV cache reuse makes the runtime safer under concurrency pressure.
- Blackwell-aware kernel work suggests a serious focus on modern NVIDIA hardware.
- Split control-plane architecture keeps latency-sensitive scheduling separate from model execution.
- Preview docs with multiple guides make it easier to reproduce the published benchmarks and server setup.
Cons:
- Not production-ready yet, and the repo explicitly warns against using the preview release for deployments.
- Incomplete model coverage means the current branch does not yet cover the full intended matrix.
- Runtime features are still in flight, including PD, EPLB, KV store, Mamba cache, VLM, and metrics.
- Hardware optimization is still expanding, with Hopper and MI350 work still being cleaned up.
- Lower ecosystem maturity than vLLM or TensorRT-LLM, so you should expect more validation work before rollout.
Getting Started with TokenSpeed
git clone https://github.com/lightseekorg/tokenspeed.git
cd tokenspeed
python -m pip install -e .
tokenspeed serve --model Qwen/Qwen2.5-32B-Instruct --config configs/server.yaml
After that, check the TokenSpeed docs index, getting-started guide, launching guide, and model recipes to match your target model and GPU topology. The first real task is usually validating parallelism settings, KV cache behavior, and kernel selection against the exact model you want to serve.
Verdict
TokenSpeed is the strongest option for teams benchmarking next-gen agentic serving stacks when they need Blackwell-targeted throughput and can tolerate preview-stage APIs. Its main strength is the compiler-plus-scheduler design; its caveat is incomplete model coverage and unfinished runtime features. Use TokenSpeed for evaluation and architecture work, not production.